Clients and entities
Anything that connects and authenticates to Vault to accomplish a task is a client. For example, a user logging into a cluster to manage policies or a machine-based system (application or cloud service) requesting a database token are both considered clients.
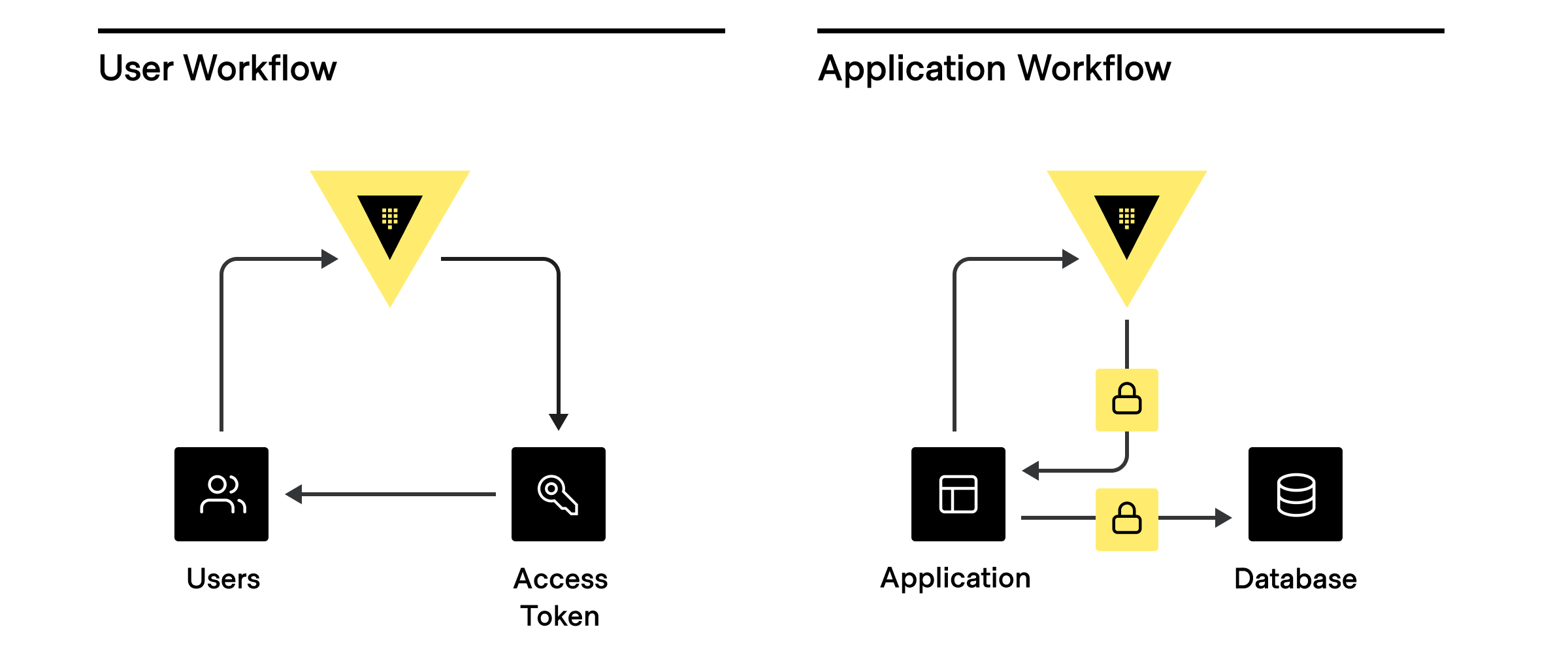
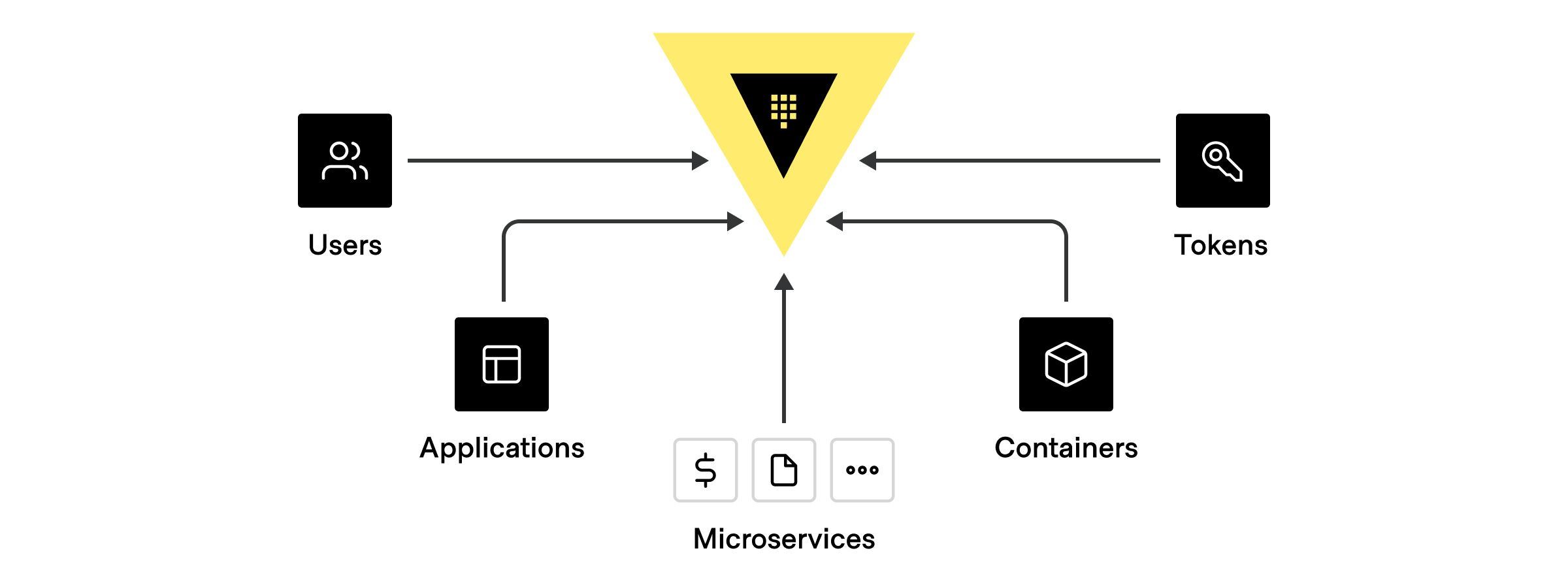
While there are many different potential clients, the most common are:
- Human users interacting directly with Vault.
- Applications and microservices.
- Servers and platforms like VMs, Docker containers, or Kubernetes pods.
- Orchestrators like Nomad, Terraform, Ansible, ACME, and other continuous integration / continuous delivery (CI/CD) pipelines.
- Vault agents and proxies that act on behalf of an application or microservice.
Identity and entity assignment
Authorized clients can connect to Vault with a variety of authentication methods.
| Authorization source | AuthN method |
|---|---|
| Externally managed or SSO | Active Directory, LDAP, OIDC, JWT, GitHub, username+password |
| Platform- or server-based | Kubernetes, AWS, GCP, Azure, Cert, Cloud Foundry |
| Self | AppRole, tokens with no associated authN path or role |
When a client authenticates, Vault assigns a unique identifier (client entity) in the Vault identity system based on the authentication method used or a previously assigned alias. Entity aliases let clients authenticate with multiple methods but still be associated with a single policy, share resources, and count as the same entity, regardless of the authentication method used for a particular session.
Standard entity assignments
In addition to custom authentication methods configured with secure plugins, Vault supports many standardized authentication methods by default.
| AuthN method | Unique ID | Configured with |
|---|---|---|
| AliCloud | Principal ID | Not configurable |
| AppRole | Role ID | Not configurable |
| AWS IAM | Vault Role ID (default), IAM unique ID, Full ARN | iam_alias |
| AWS EC2 | Vault Role ID (default), EC2 instance ID, AMI ID | ec2_alias |
| Azure | Subject (from JWT claim) | Not configurable |
| Cloud Foundry | App ID | Not configurable |
| GitHub | User login name associated with token | Not configurable |
| Google Cloud | Vault Role ID (default), Service account unique ID | iam_alias |
| JWT/OIDC | The presented claims (no default value) | user_claim |
| Kerberos | Username | Not configurable |
| Kubernetes | Service account UID (default), Service account Name | alias_name_source |
| LDAP | Username | Not configurable |
| OCI | Rolename | Not configurable |
| Okta | Username | Not configurable |
| RADIUS | Username | Not configurable |
| SAML | Assertion Subject | Not configurable |
| TLS Certificate | Subject CommonName | Not configurable |
| Token | entity_alias | Not configurable |
| Username/Password | Username | Not configurable |
Each authentication method has a unique ID string that corresponds to a client entity used for telemetry. For example, a microservice authenticating with AppRole takes the associated role ID as the entity. If you are running at scale and have multiple copies of the microservices using the same role id, the full set of instances will share the same identifier.
As a result, it is critical that you configure different clients (microservices, humans, applications, services, platforms, servers, or pipelines) in a way that results in distinct clients having unique identifiers. For example, the role IDs should be different between two microservices, MicroserviceA and MicroServiceB, even if the specific instances of MicroServiceA and MicroServiceB share a common role ID.
Entity assignment with ACME
Vault treats all ACME connections that authenticate under the same certificate identifier (domain) as the same certificate entity for client count calculations.
For example:
- ACME client requests (from the same server or separate servers) for the same certificate identifier (a unique combination of CN,DNS, SANS and IP SANS) are treated as the same entity.
- If an ACME client makes a request for
a.test.com, and subsequently makes a new request forb.test.comand*.test.comthen two distinct entities will be created, one fora.test.comand another for the combination ofb.test.comand*.test.com. - Overlap of certificate identifiers from different ACME clients will be treated
as the same entity e.g. if client 1 requests
a.test.comand client 2 requestsa.test.coma single entity is created for both requests.
Secret sync clients
Vault can automatically update secrets in external destinations with secret sync. A secret that gets synced to one or more destinations is considered a secret sync client for client count calculations.
Note that:
- Each synced secret is counted distinctly based on the path and namespace of
the secret. If you have secrets at path
kv1/secretandkv2/secretwhich are both synced, then two distinct secret syncs will be counted. - A secret can be synced to multiple different destinations, and it will still
only be counted as one secret sync. If
kv/secretis synced to both Azure Key Vault and AWS Secret Manager, this will be counted as only one secret sync client. - Secret sync clients are only created after you create an association between a
secret and a store. If you create
kv/secretand do not associate this secret with any destinations, it will not be counted as a secret sync client. - Secret syncs clients are registered in Vault's client counting system so long
as the sync is active. If you create
kv/secretand associate it with a destination in January, update the secret in May, and then delete the secret in September, Vault will consider this client as having been seen throughout the entire period of January through September.
Entity assignment with namespaces
A namespace represents a isolated, logical space within a single Vault cluster and is typically used for administrative purposes.
When a client authenticates within a given namespace, Vault assigns the same client entity to activities within any child namespaces because the namespaces exist within the same larger scope.
When a client authenticates across namespace boundaries, Vault treats the single client as two distinct entities because the client is operating across different scopes with different policy assignments and resources.
For example:
- Different requests under parent and child namespaces from a single client authenticated under the parent namespace are assigned the same entity ID. All the client activities occur within the boundaries of the namespace referenced in the original authentication request.
- Different requests under parent and child namespaces from a single client authenticated under the child namespace are assigned different entity IDs. Some of the client activities occur outside the boundaries of the namespace referenced in the original authentication request.
- Requests by the same client to two different namespaces, NAMESPACEA and NAMESPACEB are assigned different entity IDs.
Entity assignment with non-entity tokens
Vault uses tokens as the core method for authentication. You can use tokens to authenticate directly, or use token auth methods to dynamically generate tokens based on external identities.
When clients authenticate with the token auth method without a client identity, the result is a non-entity token. For example, a service might use the token authentication method to create a token for a user whose explicit identity is unknown.
Ultimately, non-entity tokens trace back to a particular client or purpose so Vault assigns unique entity IDs to non-entity tokens based on a combination of the:
- assigned entity alias name (if present),
- associated policies, and
- namespace under which the token was created.
In rare cases, tokens may be created outside of the Vault identity system without an associated entity or identity. Vault treats every unaffiliated token as a unique client for production usage. We strongly discourage the use of unaffiliated tokens and recommend that you always associate a token with an entity alias and token role.
Behavior change in Vault 1.9+
As of Vault 1.9, all non-entity tokens with the same namespace and policy assignments are treated as the same client entity. Prior to Vault 1.9, every non-entity token was treated as a unique client entity, which drastically inflated telemetry around client count.If you are using Vault 1.8 or earlier, and need to address client count inflation without upgrading, we recommend creating a token role with allowable entity aliases and assigning all tokens to an appropriate role and entity alias name before using them.
Continue reading... |
|---|